As we uncover the section of Awk features in this part of the series, we will walk through the concept of built-in variables in Awk. There are two types of variables you can use in Awk, these are; user-defined variables, which we covered in Part 8, and built-in variables.
Built-in variables have values already defined in Awk, but we can also carefully alter those values, the built-in variables include:
FILENAME: current input file name( do not change variable name)FR: number of the current input line (that is input line 1, 2, 3… so on, do not change variable name)NF: number of fields in current input line (do not change variable name)OFS: output field separatorFS: input field separatorORS: output record separatorRS: input record separator
Let us proceed to illustrate the use of some of the Awk built-in variables above:
To read the filename of the current input file, you can use the FILENAME built-in variable as follows:
awk ' { print FILENAME } ' ~/domains.txt
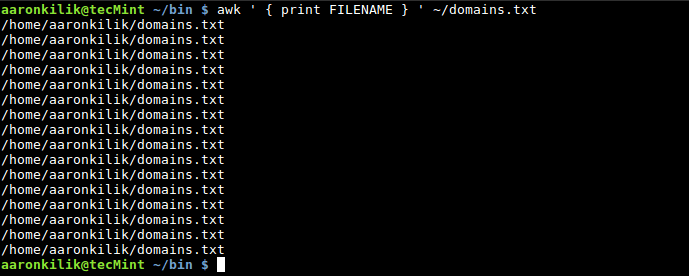
You will see that the filename is printed for each input line. This is the default behavior of Awk when using the FILENAME built-in variable.
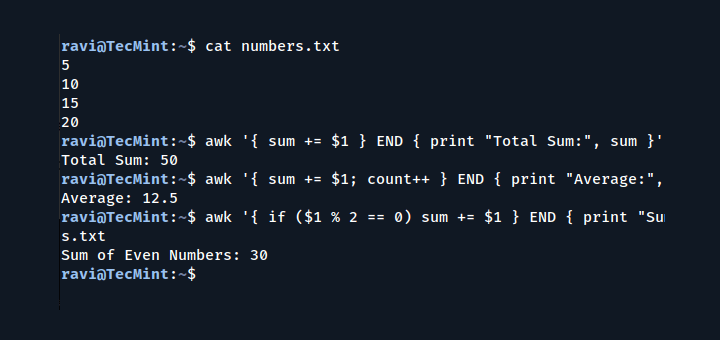
Using NR to count the number of lines (records) in an input file, remember that, it also counts the empty lines, as we shall see in the example below.
When we view the file domains.txt using the cat command, it contains 14 lines with text and empty 2 lines:
cat ~/domains.txt

To count the number of records, use the NR built-in variable as follows:
awk ' END { print "Number of records in file is: ", NR } ' ~/domains.txt

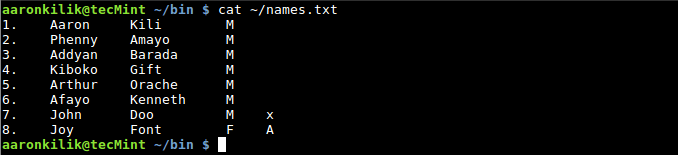
To count the number of fields in a record or line, we use the NR built-in variable as follows:
$ cat ~/names.txt
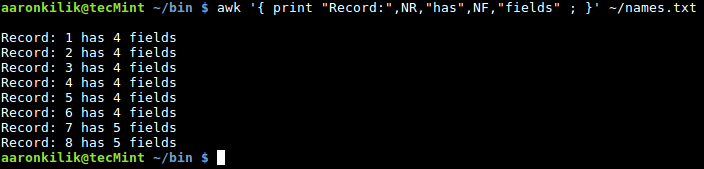
To count the number of fields in each record or line, use the NF built-in variable:
awk '{ print "Record:",NR,"has",NF,"fields" ; }' ~/names.txt
Next, you can also specify an input field separator using the FS built-in variable, it defines how Awk divides input lines into fields.
The default value for FS is space and tab, but we can change the value of FS to any character that will instruct Awk to divide input lines accordingly.
There are two methods to do this:
- one method is to use the
FSbuilt-in variable - and the second is to invoke the
-FAwk option
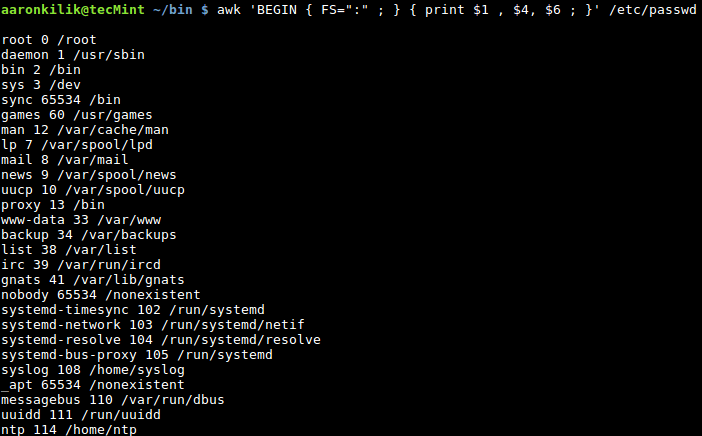
Consider the file /etc/passwd on a Linux system, the fields in this file are divided using the : character, so we can specify it as the new input field separator when we want to filter out certain fields as in the following examples:
We can use the -F option as follows:
awk -F':' '{ print $1, $4 ;}' /etc/passwd

Optionally, we can also take advantage of the FS built-in variable as below:
awk ' BEGIN { FS=“:” ; } { print $1, $4 ; } ' /etc/passwd
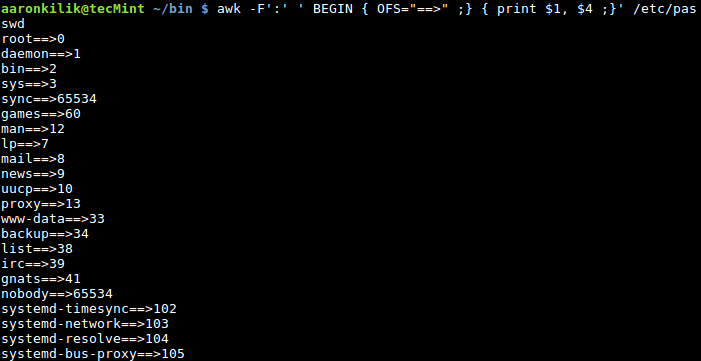
To specify an output field separator, use the OFS built-in variable, it defines how the output fields will be separated using the character we use as in the example below:
awk -F':' ' BEGIN { OFS="==>" ;} { print $1, $4 ;}' /etc/passwd
In Part 10, we have explored the idea of using Awk built-in variables which come with predefined values. But we can also change these values, though, it is not recommended to do so unless you know what you are doing, with adequate understanding.
After this, we shall progress to cover how we can use shell variables in Awk command operations and, therefore, stay connected to Tecmint.
For those seeking a comprehensive resource, we’ve compiled all the Awk series articles into a book, that includes 13 chapters and spans 41 pages, covering both basic and advanced Awk usage with practical examples.
| Product Name | Price | Buy |
|---|---|---|
| eBook: Introducing the Awk Getting Started Guide for Beginners | $8.99 | [Buy Now] |