Scikit-learn is one of the most popular machine learning libraries for Python, which provides a wide range of tools for data analysis and machine learning tasks, from simple linear regression to advanced clustering algorithms.
This article will guide you through the steps to install and use Scikit-learn on a Linux system.
What is Scikit-learn?
Scikit-learn (also known as sklearn) is a free, open-source Python library used for machine learning tasks. It builds on other Python libraries like NumPy, SciPy, and matplotlib, offering a simple interface for complex machine learning algorithms.
Some of the key features of Scikit-learn include:
- Supervised learning (e.g., classification, regression).
- Unsupervised learning (e.g., clustering, dimensionality reduction)
- Model evaluation and validation
- Data preprocessing tools
- Support for multiple data formats and tools for model deployment
Installing Python in Linux
Scikit-learn is built on Python, so you need to have Python installed on your system. You can check if Python is already installed by typing the following command in your terminal:
python3 --version
If Python is not installed, you can install it by running:
sudo apt install python3 [On Debian, Ubuntu and Mint] sudo yum install python3 [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] sudo emerge -a sys-apps/python3 [On Gentoo Linux] sudo apk add python3 [On Alpine Linux] sudo pacman -S python3 [On Arch Linux] sudo zypper install python3 [On OpenSUSE] sudo pkg install python3 [On FreeBSD]
Installing Pip in Linux
Pip is the Python package manager used to install Python libraries like Scikit-learn. To check if pip is installed, run:
pip3 --version
If pip is not installed, install it using:
sudo apt install python3-pip [On Debian, Ubuntu and Mint] sudo yum install python3-pip [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] sudo emerge -a dev-python/pip [On Gentoo Linux] sudo apk add py3-pip [On Alpine Linux] sudo pacman -S python-pip [On Arch Linux] sudo zypper install python3-pip [On OpenSUSE] sudo pkg install py38-pip [On FreeBSD]
Installing Scikit-learn in Linux
Now create a virtual environment (venv) and install scikit-learn. Note that the virtual environment is optional but strongly recommended, in order to avoid potential conflicts with other packages.
python3 -m venv sklearn-env source sklearn-env/bin/activate pip3 install -U scikit-learn
This command will download and install the latest version of Scikit-learn along with its dependencies (such as NumPy and SciPy). Depending on your internet speed, this may take a few minutes.
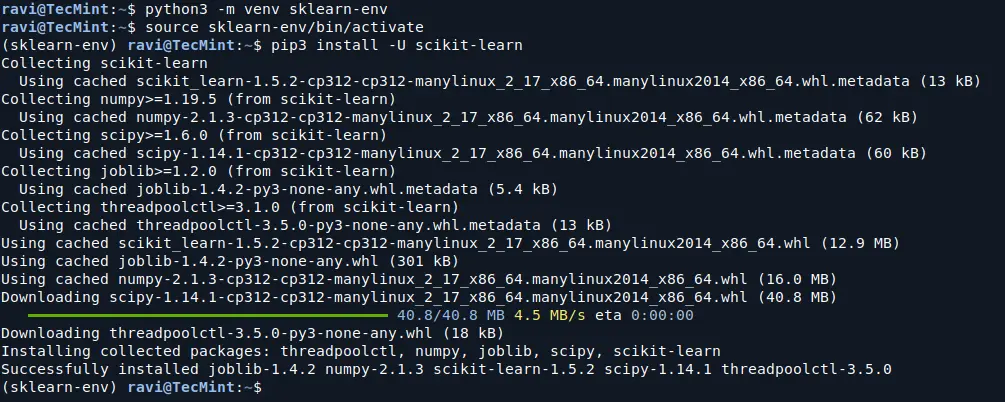
After the installation is complete, you can verify that Scikit-learn is installed correctly by importing it in Python.
python3 -m pip show scikit-learn # show scikit-learn version and location python3 -m pip freeze # show all installed packages in the environment python3 -c "import sklearn; sklearn.show_versions()"
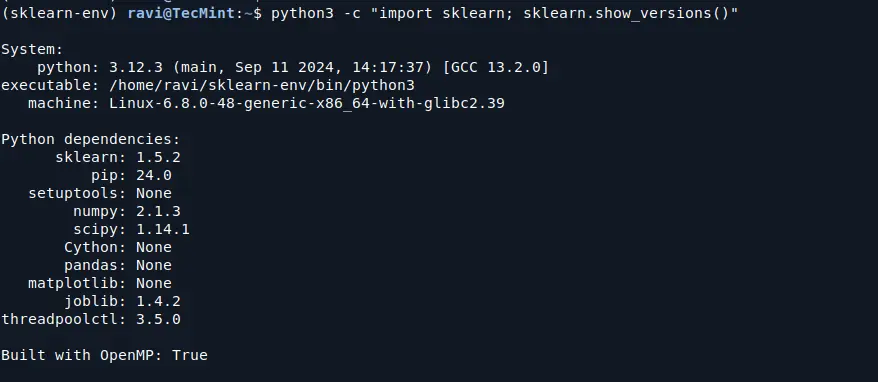
If no errors appear and the version number of Scikit-learn is printed, the installation is successful.
How to Use Scikit-learn in Linux
Once you’ve installed Scikit-learn, it’s time to start using it with the below basic examples of how to use Scikit-learn for various machine learning tasks.
Example 1: Importing Scikit-learn and Loading a Dataset
Scikit-learn provides several built-in datasets for learning purposes. One popular dataset is the “Iris” dataset, which contains data about different species of iris flowers.
To load the Iris dataset, use the following code:
from sklearn.datasets import load_iris # Load the dataset iris = load_iris() # Print the features and target labels print(iris.data) print(iris.target)
Example 2: Splitting Data into Training and Test Sets
Before applying machine learning models, it’s important to split the dataset into training and test sets, which ensures that the model is trained on one subset of the data and tested on another, preventing overfitting.
You can use train_test_split from Scikit-learn to split the data:
from sklearn.model_selection import train_test_split
# Split the data into 80% training and 20% testing
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
print("Training data:", X_train.shape)
print("Testing data:", X_test.shape)
Example 3: Training a Machine Learning Model
Now, let’s train a machine learning model with the help of a simple classifier, such as a Support Vector Machine (SVM), to classify the iris flowers.
from sklearn.svm import SVC
# Create an SVM classifier
model = SVC()
# Train the model on the training data
model.fit(X_train, y_train)
# Predict on the test data
y_pred = model.predict(X_test)
print("Predicted labels:", y_pred)
Example 4: Evaluating the Model
After training the model, it’s important to evaluate its performance. You can use metrics like accuracy to see how well the model is performing.
from sklearn.metrics import accuracy_score
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
This will print the accuracy of the model, which represents the percentage of correct predictions made by the model on the test data.
Conclusion
In this article, we’ve covered how to install and use Scikit-learn on a Linux system. We showed how to install it using pip, load datasets, split data, train machine learning models, and evaluate the model’s performance.
Scikit-learn is a powerful and easy-to-use tool for machine learning in Python. With the steps outlined above, you can get started on your machine learning journey and explore the vast range of algorithms and techniques Scikit-learn offers.
By practicing and experimenting with different algorithms, datasets, and model evaluation techniques, you’ll be able to build effective machine learning solutions for real-world problems.





