We are living in a world where data is growing in an unpredictable way and it our need to store this data, whether it is structured or unstructured, in an efficient manner. Distributed computing systems offer a wide array of advantages over centralized computing systems. Here data is stored in a distributed way with several nodes as servers.

The concept of a metadata server is no longer needed in a distributed file system. In distributed file systems, it offers a common view point of all the files separated among different servers. Files/directories on these storage servers are accessed in normal ways.
For example, the permissions for files/directories can be set as in usual system permission model, i.e. the owner, group and others. The access to the file system basically depends on how the particular protocol is designed to work on the same.
What is GlusterFS?
GlusterFS is a distributed file system defined to be used in user space, i.e. File System in User Space (FUSE). It is a software based file system which accounts to its own flexibility feature.
Look at the following figure which schematically represents the position of GlusterFS in a hierarchical model. By default TCP protocol will be used by GlusterFS.
Advantages to GlusterFS
- Innovation – It eliminates the metadata and can dramtically improve the performance which will help us to unify data and objects.
- Elasticity – Adapted to growth and reduction of size of the data.
- Scale Linearly – It has availability to petabytes and beyond.
- Simplicity – It is easy to manage and independent from kernel while running in user space.
What makes Gluster outstanding among other distributed file systems?
- Salable – Absence of a metadata server provides a faster file system.
- Affordable – It deploys on commodity hardware.
- Flexible – As I said earlier, GlusterFS is a software only file system. Here data is stored on native file systems like ext4, xfs etc.
- Open Source – Currently GlusterFS is maintained by Red Hat Inc, a billion dollar open source company, as part of Red Hat Storage.
Storage concepts in GlusterFS
- Brick – Brick is basically any directory that is meant to be shared among the trusted storage pool.
- Trusted Storage Pool – is a collection of these shared files/directories, which are based on the designed protocol.
- Block Storage – They are devices through which the data is being moved across systems in the form of blocks.
- Cluster – In Red Hat Storage, both cluster and trusted storage pool convey the same meaning of collaboration of storage servers based on a defined protocol.
- Distributed File System – A file system in which data is spread over different nodes where users can access the file without knowing the actual location of the file. User doesn’t experience the feel of remote access.
- FUSE – It is a loadable kernel module which allows users to create file systems above kernel without involving any of the kernel code.
- glusterd – glusterd is the GlusterFS management daemon which is the backbone of file system which will be running throughout the whole time whenever the servers are in active state.
- POSIX – Portable Operating System Interface (POSIX) is the family of standards defined by the IEEE as a solution to the compatibility between Unix-variants in the form of an Application Programmable Interface (API).
- RAID – Redundant Array of Independent Disks (RAID) is a technology that gives increased storage reliability through redundancy.
- Subvolume – A brick after being processed by least at one translator.
- Translator – A translator is that piece of code which performs the basic actions initiated by the user from the mount point. It connects one or more sub volumes.
- Volume – A volumes is a logical collection of bricks. All the operations are based on the different types of volumes created by the user.
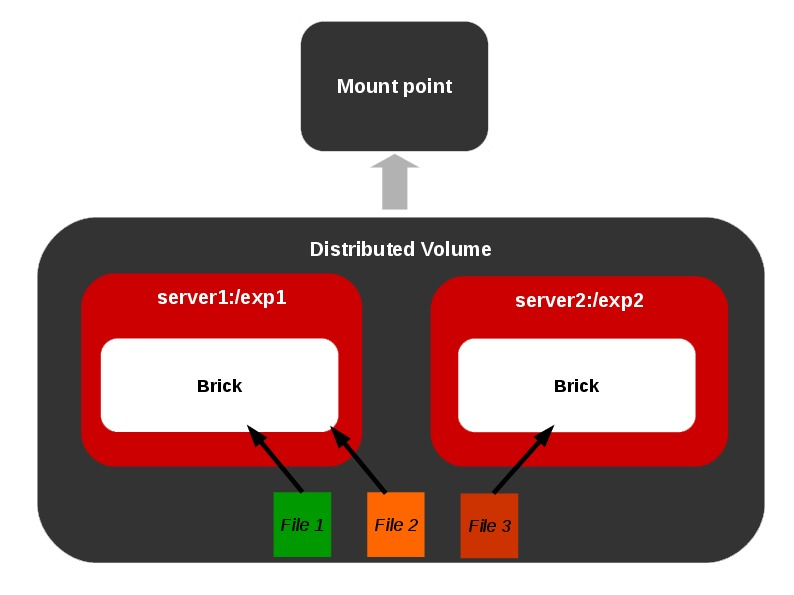
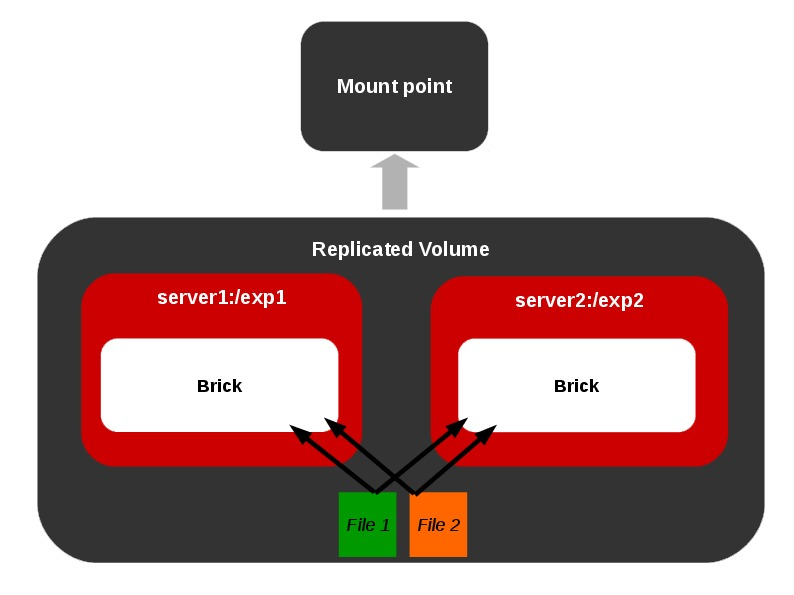
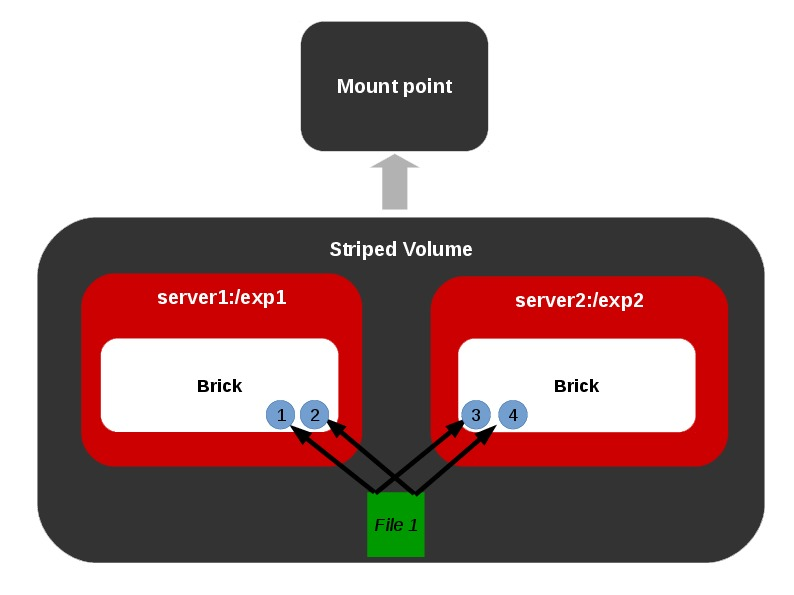
Different Types of Volumes
Representations of different types of volumes and combinations among these basic volume types are also allowed as shown below.
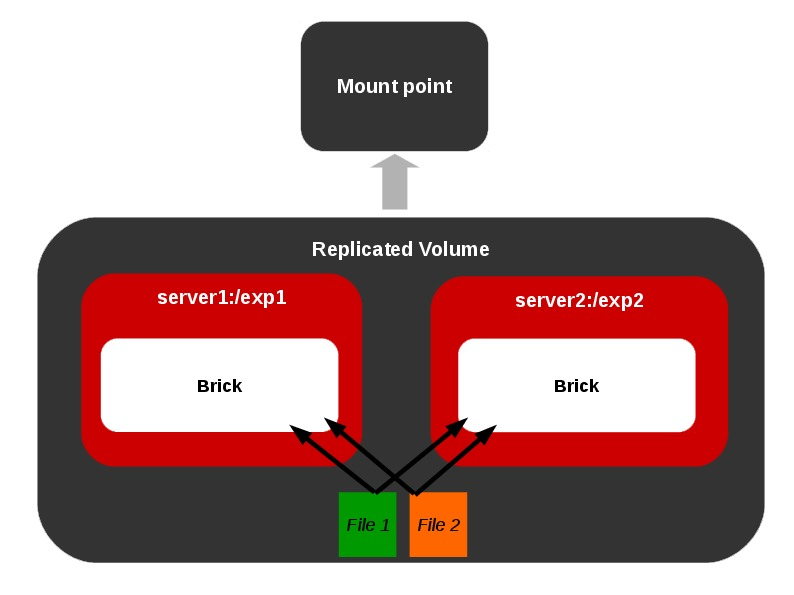
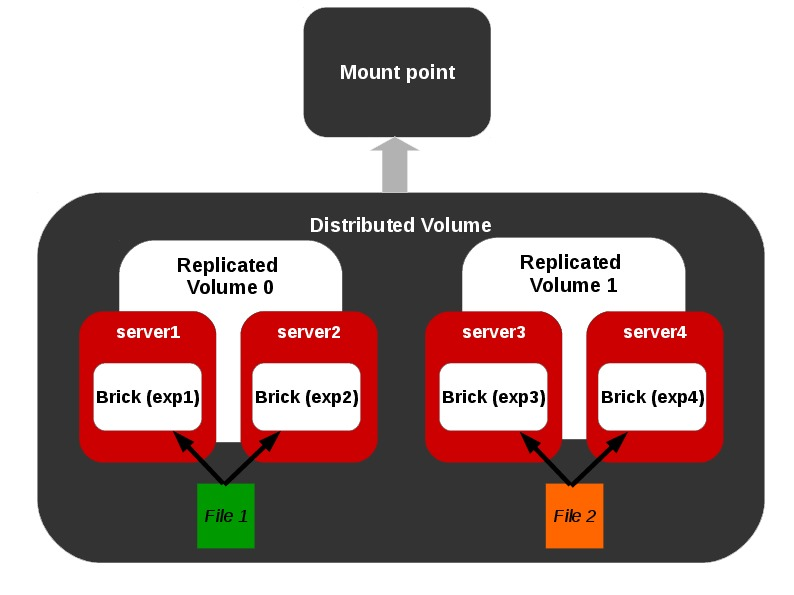
Distributed Replicated Volume
Representation of a distributed-replicated volume.
Installation of GlusterFS in RHEL/CentOS and Fedora
In this article, we will be installing and configuring GlusterFS for the first time for high availability of storage. For this, we’re taking two servers to create volumes and replicate data between them.
Step :1 Have at least two nodes
- Install CentOS 6.5 (or any other OS) on two nodes.
- Set hostnames named “server1” and “server2“.
- A working network connection.
- Storage disk on both nodes named “/data/brick“.
Step 2: Enable EPEL and GlusterFS Repository
Before Installing GlusterFS on both the servers, we need to enable EPEL and GlusterFS repositories in order to satisfy external dependencies. Use the following link to install and enable epel repository under both the systems.
Next, we need to enable GlusterFs repository on both servers.
# wget -P /etc/yum.repos.d http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/glusterfs-epel.repo
Step 3: Installing GlusterFS
Install the software on both servers.
# yum install glusterfs-server
Start the GlusterFS management daemon.
# service glusterd start
Now check the status of daemon.
# service glusterd status
Sample Output
service glusterd start service glusterd status glusterd.service - LSB: glusterfs server Loaded: loaded (/etc/rc.d/init.d/glusterd) Active: active (running) since Mon, 13 Aug 2012 13:02:11 -0700; 2s ago Process: 19254 ExecStart=/etc/rc.d/init.d/glusterd start (code=exited, status=0/SUCCESS) CGroup: name=systemd:/system/glusterd.service ├ 19260 /usr/sbin/glusterd -p /run/glusterd.pid ├ 19304 /usr/sbin/glusterfsd --xlator-option georep-server.listen-port=24009 -s localhost... └ 19309 /usr/sbin/glusterfs -f /var/lib/glusterd/nfs/nfs-server.vol -p /var/lib/glusterd/...
Step 4: Configure SELinux and iptables
Open ‘/etc/sysconfig/selinux‘ and change SELinux to either “permissive” or “disabled” mode on both the servers. Save and close the file.
# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targeted
Next, flush the iptables in both nodes or need to allow access to the other node via iptables.
# iptables -F
Step 5: Configure the Trusted Pool
Run the following command on ‘Server1‘.
gluster peer probe server2
Run the following command on ‘Server2‘.
gluster peer probe server1
Note: Once this pool has been connected, only trusted users may probe new servers into this pool.
Step 6: Set up a GlusterFS Volume
On both server1 and server2.
# mkdir /data/brick/gv0
Create a volume On any single server and start the volume. Here, I’ve taken ‘Server1‘.
# gluster volume create gv0 replica 2 server1:/data/brick1/gv0 server2:/data/brick1/gv0 # gluster volume start gv0
Next, confirm the status of volume.
# gluster volume info
Note: If in-case volume is not started, the error messages are logged under ‘/var/log/glusterfs‘ on one or both the servers.
Step 7: Verify GlusterFS Volume
Mount the volume to a directory under ‘/mnt‘.
# mount -t glusterfs server1:/gv0 /mnt
Now you can create, edit files on the mount point as a single view of the file system.
Features of GlusterFS
- Self-heal – If any of the bricks in a replicated volume are down and users modify the files within the other brick, the automatic self-heal daemon will come into action as soon as the brick is up next time and the transactions occurred during the down time are synced accordingly.
- Rebalance – If we add a new brick to an existing volume, where large amount of data was previously residing, we can perform a rebalance operation to distribute the data among all the bricks including the newly added brick.
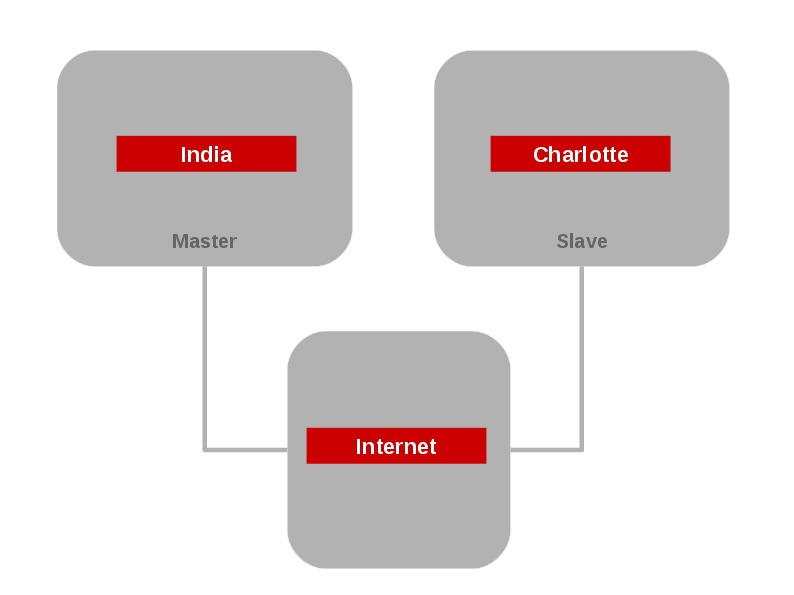
- Geo-replication – It provides back-ups of data for disaster recovery. Here comes the concept of master and slave volumes. So that if master is down whole of the data can be accessed via slave. This feature is used to sync data between geographically separated servers. Initializing a geo-replication session requires a series of gluster commands.
Here, is the following screen grab that shows the Geo-replication module.
Reference Links
That’s it for now!. Stay updated for the detailed description on features like Self-heal and Re-balance, Geo-replication, etc in my upcoming articles.