The Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, a new program that aims at helping individuals all over the world to get certified in basic to intermediate system administration tasks for Linux systems.
This includes supporting running systems and services, along with first-hand troubleshooting and analysis, and smart decision-making to escalate issues to engineering teams.
The series will be titled Preparation for the LFCS (Linux Foundation Certified Sysadmin) Parts 1 through 33 and cover the following topics:
This post is Part 1 of a 33-tutorial series, which will cover the necessary domains and competencies that are required for the LFCS certification exam. That being said, fire up your terminal, and let’s start.
Processing Text Streams in Linux
Linux treats the input to and the output from programs as streams (or sequences) of characters. To begin understanding redirection and pipes, we must first understand the three most important types of I/O (Input and Output) streams, which are in fact special files (by convention in UNIX and Linux, data streams and peripherals, or device files, are also treated as ordinary files).
The difference between > (redirection operator) and | (pipeline operator) is that while the first connects a command with a file, the latter connects the output of a command with another command.
# command > file # command1 | command2
Since the redirection operator creates or overwrites files silently, we must use it with extreme caution, and never mistake it with a pipeline.
One advantage of pipes on Linux and UNIX systems is that there is no intermediate file involved with a pipe – the stdout of the first command is not written to a file and then read by the second command.
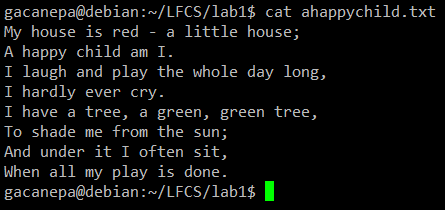
For the following practice exercises, we will use the poem “A happy child” (anonymous author).
Using sed Command
The name sed is short for stream editor. For those unfamiliar with the term, a stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline).
Change Lowercase to Uppercase in File
The most basic (and popular) usage of sed is the substitution of characters. We will begin by changing every occurrence of the lowercase y to UPPERCASE Y and redirecting the output to ahappychild2.txt.
The g flag indicates that sed should perform the substitution for all instances of term on every line of the file. If this flag is omitted, sed will replace only the first occurrence of the term on each line.
Sed Basic Syntax:
# sed ‘s/term/replacement/flag’ file
Our Example:
# sed ‘s/y/Y/g’ ahappychild.txt > ahappychild2.txt

Search and Replace Word in File
Should you want to search for or replace a special character (such as /, \, &) you need to escape it, in the term or replacement strings, with a backward slash.
For example, we will substitute the word and for an ampersand. At the same time, we will replace the word I with You when the first one is found at the beginning of a line.
# sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
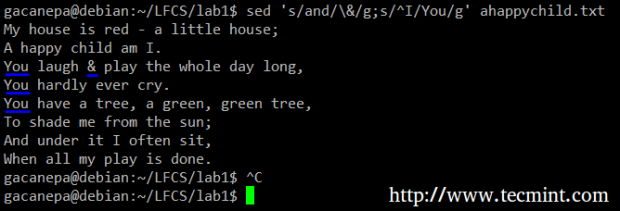
In the above command, a ^ (caret sign) is a well-known regular expression that is used to represent the beginning of a line.
As you can see, we can combine two or more substitution commands (and use regular expressions inside them) by separating them with a semicolon and enclosing the set inside single quotes.
Print Selected Lines from a File
Another use of sed is showing (or deleting) a chosen portion of a file. In the following example, we will display the first 5 lines of /var/log/messages from Jun 8.
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
Note that by default, sed prints every line. We can override this behavior with the -n option and then tell sed to print (indicated by p) only the part of the file (or the pipe) that matches the pattern (Jun 8 at the beginning of the line in the first case and lines 1 through 5 inclusive in the second case).
Finally, it can be useful while inspecting scripts or configuration files to inspect the code itself and leave out comments. The following sed one-liner deletes (d) blank lines or those starting with # (the | character indicates a boolean OR between the two regular expressions).
# sed '/^#\|^$/d' apache2.conf

uniq Command
The uniq command allows us to report or remove duplicate lines in a file, writing to stdout by default. We must note that uniq does not detect repeated lines unless they are adjacent.
Thus, uniq is commonly used along with a preceding sort (which is used to sort lines of text files). By default, sort takes the first field (separated by spaces) as a key field. To specify a different key field, we need to use the -k option.
Uniq Command Examples
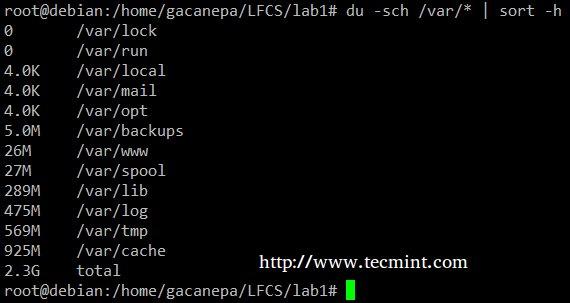
The du -sch /path/to/directory/* command returns the disk space usage per subdirectories and files within the specified directory in human-readable format (also shows a total per directory), and does not order the output by size, but by subdirectory and file name.
We can use the following command to sort by size.
# du -sch /var/* | sort –h
You can count the number of events in a log by date by telling uniq to perform the comparison using the first 6 characters (-w 6) of each line (where the date is specified), and prefixing each output line by the number of occurrences (-c) with the following command.
# cat /var/log/mail.log | uniq -c -w 6

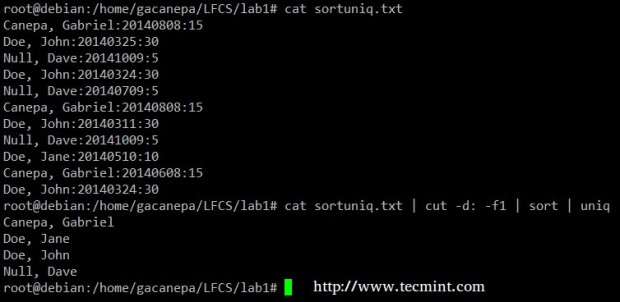
Finally, you can combine sort and uniq (as they usually are). Consider the following file with a list of donors, donation date, and amount. Suppose we want to know how many unique donors there are.
We will use the following cat command to cut the first field (fields are delimited by a colon), sort by name, and remove duplicate lines.
# cat sortuniq.txt | cut -d: -f1 | sort | uniq
grep Command
The grep command searches text files or (command output) for the occurrence of a specified regular expression and outputs any line containing a match to standard output.
Grep Command Examples
Display the information from /etc/passwd for user gacanepa, ignoring case.
# grep -i gacanepa /etc/passwd

Show all the contents of /etc whose name begins with rc followed by any single number.
# ls -l /etc | grep rc[0-9]

tr Command Usage
The tr command can be used to translate (change) or delete characters from stdin, and write the result to stdout.
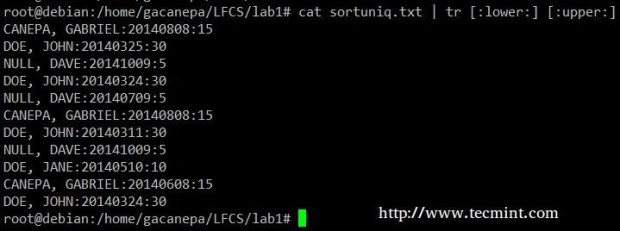
Change all lowercase to uppercase in the sortuniq.txt file.
# cat sortuniq.txt | tr [:lower:] [:upper:]
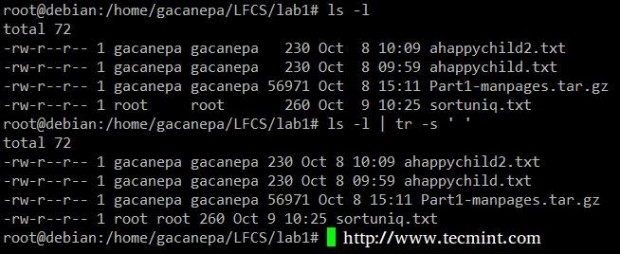
Squeeze the delimiter in the output of ls –l to only one space.
# ls -l | tr -s ' '
Cut Command Usage
The cut command extracts portions of input lines (from stdin or files) and displays the result on standard output, based on the number of bytes (-b option), characters (-c), or fields (-f).
In this last case (based on fields), the default field separator is a tab, but a different delimiter can be specified by using the -d option.
Cut Command Examples
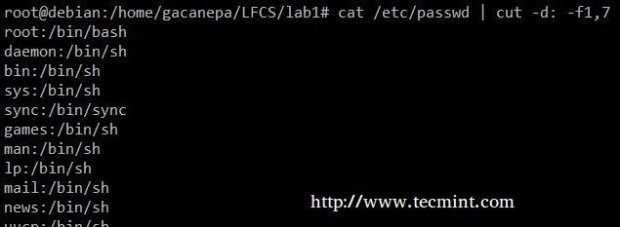
Extract the user accounts and the default shells assigned to them from /etc/passwd (the –d option allows us to specify the field delimiter and the –f switch indicates which field(s) will be extracted.
# cat /etc/passwd | cut -d: -f1,7
Summing up, we will create a text stream consisting of the first and third non-blank files of the output of the last command. We will use grep as a first filter to check for sessions of user gacanepa, then squeeze delimiters to only one space (tr -s ‘ ‘).
Next, we’ll extract the first and third fields with cut, and finally sort by the second field (IP addresses in this case) showing unique.
# last | grep gacanepa | tr -s ' ' | cut -d' ' -f1,3 | sort -k2 | uniq
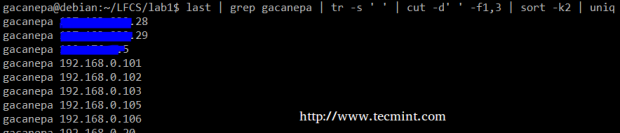
The above command shows how multiple commands and pipes can be combined so as to obtain filtered data according to our desires. Feel free to also run it by parts, to help you see the output that is pipelined from one command to the next (this can be a great learning experience, by the way!).
Summary
Although this example (along with the rest of the examples in the current tutorial) may not seem very useful at first sight, they are a nice starting point to begin experimenting with commands that are used to create, edit, and manipulate files from the Linux command line.
Feel free to leave your questions and comments below – they will be much appreciated!
The LFCS eBook is available now for purchase. Order your copy today and start your journey to becoming a certified Linux system administrator!
| Product Name | Price | Buy |
|---|---|---|
| The Linux Foundation’s LFCS Certification Preparation Guide | $19.99 | [Buy Now] |
Last, but not least, please consider buying your exam voucher using the following links to earn us a small commission, which will help us keep this book updated.






