Are you worried about transferring or uploading large files over a network? Worry no more, because you can move your files in bits to deal with slow network speeds by splitting them into blocks of a given size.
In this how-to guide, we will briefly explore the creation of archive files and splitting them into blocks of a selected size. We will use tar, one of the most popular archiving utilities on Linux, and also take advantage of the split utility to help us break our archive files into small parts.
Splitting tar Archives into Multiple Parts on Linux
Before we move further, let us take note of, how these utilities can be used, the general syntax of a tar and split command is as follows:
tar options archive-name files split options file "prefix”
Let us now delve into a few examples to illustrate the main concept of this article.
Example 1: Splitting tar File into 10MB Parts
We can first of all create an archive file as follows:
tar -cvjf home.tar.bz2 /home/aaronkilik/Documents/*
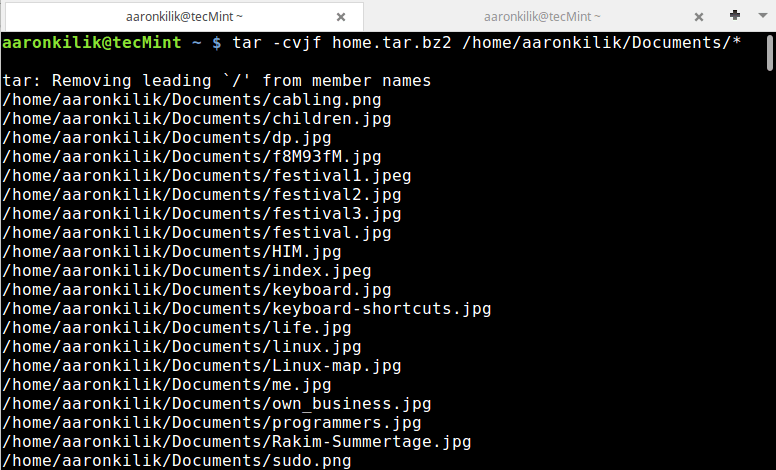
To confirm that our archive file has been created and also check its size, we can use the ls command:
ls -lh home.tar.bz2
Then using the split utility, we can break the home.tar.bz2 archive file into small blocks each of size 10MB as follows:
split -b 10M home.tar.bz2 "home.tar.bz2.part" ls -lh home.tar.bz2.parta*
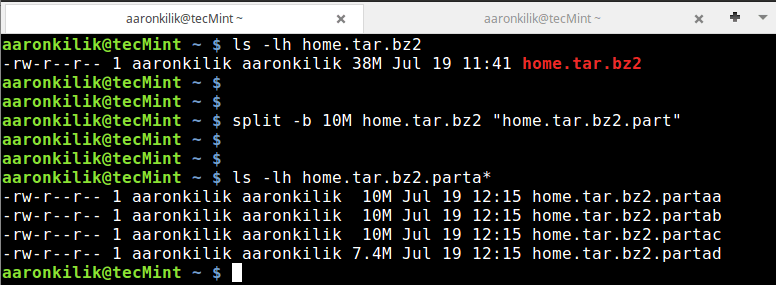
As you can see from the output of the commands above, the tar archive file has been split into four parts.
Note: In the split command above, the option -b is used to specify the size of each block and the "home.tar.bz2.part" is the prefix in the name of each block file created after splitting.
Example 2: Splitting ISO Image File into Parts
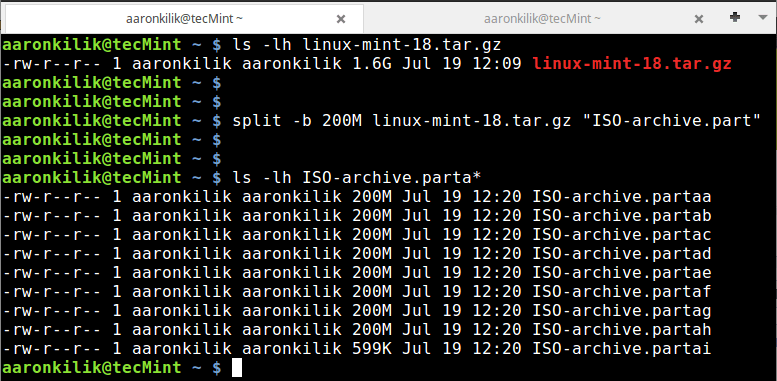
Similar to the case above, here, we can create an archive file of a Linux Mint ISO image file.
tar -cvzf linux-mint-18.tar.gz linuxmint-18-cinnamon-64bit.iso
Then follow the same steps in example 1 above to split the archive file into small bits of size 200MB.
ls -lh linux-mint-18.tar.gz split -b 200M linux-mint-18.tar.gz "ISO-archive.part" ls -lh ISO-archive.parta*
Example 3: Splitting Large Files into Smaller Parts
In this instance, we can use a pipe to connect the output of the tar command to split as follows:
tar -cvzf - wget/* | split -b 150M - "downloads-part"
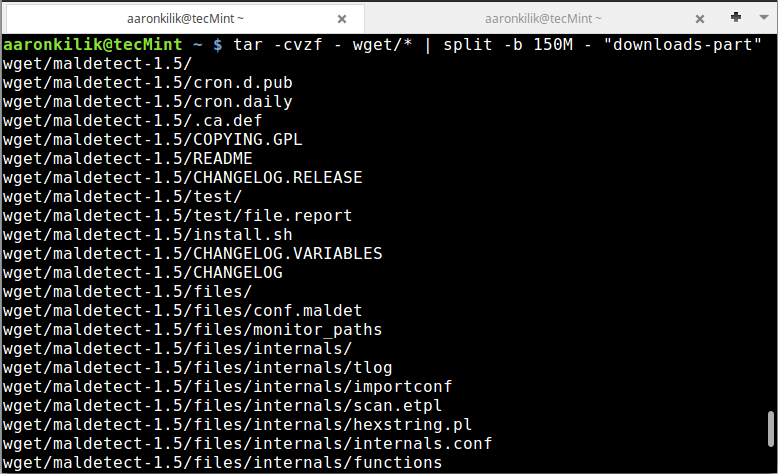
Confirm the files:
ls -lh downloads-parta*

In this last example, we do not have to specify an archive name as you have noticed, simply use a - sign.
How to Join Tar Files After Splitting
After successfully splitting tar files or any large file in Linux, you can join the files using the cat command. Employing a cat is the most efficient and reliable method of performing a joining operation.
To join back all the blocks or tar files, we issue the command below:
cat home.tar.bz2.parta* >backup.tar.gz.joined
We can see that after running the cat command, it combines all the small blocks we had earlier on created into the original tar archive file of the same size.
Conclusion
The whole idea is simple, as we have illustrated above, you simply need to know and understand how to use the various options of tar and split utilities.
You can refer to their manual entry pages of to learn more about other options and perform some complex operations or you can go through the following article to learn more about tar command.
For any questions or further tips, you can share your thoughts via the comment section below.





Hello, I have a situation. Here, I need to split up the large file in such a way that each of the “part” files generated are valid tar archives. For example:- If I do “tar -xvf home.tar.bz2.parta” it should provide the valid output of the 10MB files captured by this part itself.
You can split a potentially large tar file into multiple sub tar volumes using the
tar -M -l -Fswitches.-M= multi-volume mode.-l= volume size limit (per volume file).-F= script to switch out the current tar name to the next on in your sequence (eg you might have started with xyz.tar and when you get to the specified volume size limit, tar will call your script (-F). your script should mv that xyz.tar to something like xyzzy-001.tar and then return.tar will create a new file called xyz.tar and file it to the volume limit and call your script again which, this time, should increment the count and mv the file to xyz-002 etc. at the end you might want to have a symlink pointing the first tar vol xyz.tar –> xyz-001.tar
hope this helps
FYI if you’re on Mac, it like lower case units for the size of the split (ie. m instead of M or gb instead of GB). Otherwise, you get a nice “illegal byte count error“
Hey, If any users want Split the large PST file then I suggested trying to use Outlook PST Splitter. This Splitter breaks the large PST files into small PST files by date, size, year, and folder according to the user’s needs.
This Software Splits the files without installing MS-Outlook. This Splitter support all the Window Version and Outlook Version. This splitter has also a free version which helps users can easily see the demo before the conversion.
wow after three years no one noticed that the join command had error in the wildcard. should have been part* instead of parta*. also there are a few more errors in the article, such as “begin with .php” instead of “ended with .php” also several truncated commands and mixed-mashed command and switches which might mess up on some distribution. for example the .flv extract is nowhere specified on command line, you might mean “video directory” not *.flv. i count eight errors in total, this article seriously needed polish. i might point out the rest if this comment is approved, or someone else could also can.
@Reza
Thanks for the reporting this, we will cross check and correct the article as soon as possible. We truly appreciate your efforts.
wow i can’t believe that no one actually noticed after the years that the join command has error in the wildcard. you’ll get only the fraction of the file if you do:
should have been:
@Reza
Okay, many thanks for the heads up. We will cross check this and correct in the article.
There is a tool calld tarsplitter for permanently splitting a tar into into roughly equal sized parts. Slightly different than what is described here.
@Greg
Thanks a lot for sharing, we will check it out.
Arron well done. Terse and accurate. No mention of tar -p option. Re io performance, the – option means only compressed bits are written. gzip -9 minimizes bits to write.
The most io performance pipe is something like.
@Chris
Thanks a lot for sharing this, we will test it.
It might be a very silly question.
I have more than 1,00,000 files in a directory(60GB data) and I want to tar them based on size 128 MB.
What will happen to the file on the tape boundary .
I mean if the 500th file is tarred at around 116MB but the file size is 15 MB will the file get corrupted or the system understands that the file cannot be accommodated in that part and puts it in the next part.
@sunny
Tar will create many tar balls of 128 MB and a few, less than that size. It is intelligent enough to allocate all your 100,000 files so that no file(s) are corrupted.
Thanks Aaron.
I am also experiencing very slow speeds while tarring so many files and such huge data.
For 7,00,000 (50gb) the system is taking 20 hours . Is there a way I can speed this up
@sunny
If you are using tar without compression, the operation will be a little faster. But enabling compression slows down the whole process; for instance if you are using gzip, include the – -best or – -fast flag to make it faster(read man page for more info).
Secondly, also ensure that there is not a lot of I/O operations running on the system, or any other CPU-time consuming processes.
Is this applicable for binary files, like oracle rman backup?
@Jundi
It should be, because here, the operation splits the archive file into pieces, not the individual files that make up the package file(tarball).
How do we combine the “Parallel Implementation of GZip” here…
It would be better to use gzip compression when planning on splitting. The reason being is the parts could still be used without the need to region the files.
e.g. (cat filea fileb filec filed)|tar – xfz
The same procedure does not work with bzip2 files, as bunzip2 requires a memory mapping of the files.
You can also if you want to the gzip after splitting, as when concat gzip files together, the procedure still works exactly as described above.
@Bill
Many thanks for the useful suggestion, i hope users will follow this method as well.
This is an effective explanation of a solution to a common problem. There is another side to these issues that involves initial creation of the large tar archive. The processing to create the archive is likely to take a long time (wall clock). Various events might interrupt that processing before it is complete. Example interruptions might include loss of power, battery depletion, loss of connection to the target disk(s), and so on.
The tar command does not have the ability to remember which input files and folders have already been processed and resume with the remaining to-be-done files and folders. Instead, the list of files submitted to tar gets determined by the input selection GLOB at the tar command line. I’m certain that readers would be interested in any technique that will enable (1) creation of a list of files, (2) gathering of checkpoint details while files are processed, (3) restart from the most recent checkpoint following an interruption.
@Dan,
I am totally agree with your point, but to be fact, it is not possible with tar command to resume broken or interrupted process and I think there isn’t any tool does the same….
@Dan St.Andre
Thanks for the appreciation, and as you well expressed your concern, i took out to search for any other powerful Unix/Linux archive creating utilities apart from TAR that can handle the issues you are trying to bring to light.
TAR is a Unix/Linux standard for this particular purpose, as far as i know(and i stand to be corrected), there is no other utility that can solve the shortcomings of TAR you have mentioned above. Probably in the future, someone will developed a utility that will resolve these issues but at the moment, that is just the way it works.
But am still on the look out to find a technique or method that you have well explained above, and in case you find one, please always let us know. Many thanks for your feedback.
The only work around that might work (not tested it personally) is snapshot recovery of a virtual machine running the task, this resilience will not completely recover from last point of blackout though, only since last successful snapshot, furthermore it might involve more resource overhead (disc space, hosting, etc, etc) than initially desired.
@Lewis
Many thanks for sharing your thoughts on the matter, as you have mentioned, it can be a long process and requires so much more resources but if necessary then a user can give it a try.
Nice explanation, but please mention how to puzzle them together again …
@Lars
Thanks for the feedback, we shall update the article to include that.
Hi, you could just issue
cat filea fileb filec filed > file.tar
And there you have your original file back.
@Leonardo,
Thanks for the tip, didn’t know about this handy trick, just we’ve included the instructions to combine or join back together files after splitting large tar archive file to the writeup….hope you like it..
@Lars,
Thanks for finding it useful, as per you request we’ve added a section to join back tar files after splitting to the writeup..