In this sixth part of the Awk series, we shall dive into the next command and see how it can be used to optimize your script executions, as this command is particularly useful for skipping unnecessary steps in processing your data.
What is the next Command?
The next command in awk tells it to skip the remaining patterns and actions for the current line and proceed to the next input line. This can help avoid executing redundant or unnecessary steps, making your scripts more efficient.
Example 1: Flagging Items Based on Quantity
Let’s start with a practical example by considering a file named food_list.txt with the following content.
Food List Items No Item_Name Price Quantity 1 Mangoes $3.45 5 2 Apples $2.45 25 3 Pineapples $4.45 55 4 Tomatoes $3.45 25 5 Onions $1.45 15 6 Bananas $3.45 30
Consider running the following command that will flag food items whose quantity is less than or equal to 20 with a (*) sign at the end of each line:
awk '$4 <= 20 { printf "%s\t%s\n", $0,"*" ; } $4 > 20 { print $0 ;}' food_list.txt
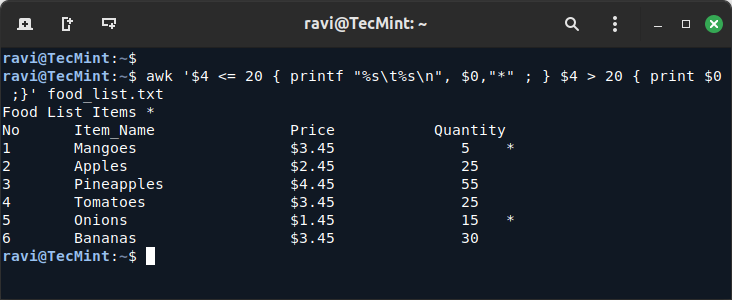
The command above actually works as follows:
- First, it checks whether the quantity, fourth field of each input line is less than or equal to 20, if a value meets that condition, it is printed and flagged with the
(*)sign at the end using expression one:$4 <= 20 - Secondly, it checks if the fourth field of each input line is greater than 20, and if a line meets the condition it gets printed using expression two:
$4 > 20
The Problem:
But there is one problem here, when the first expression is executed, a line that we want to flag is printed using: { printf "%s\t%s\n", $0,"**" ; } and then in the same step, the second expression is also checked which becomes a time-wasting factor.
So there is no need to execute the second expression, $4 > 20 again after printing already flagged lines that have been printed using the first expression.
Optimized Command Using next
To deal with this problem, you have to use the next command as follows:
awk '$4 <= 20 { printf "%s\t%s\n", $0,"*" ; next; } $4 > 20 { print $0 ;}' food_list.txt
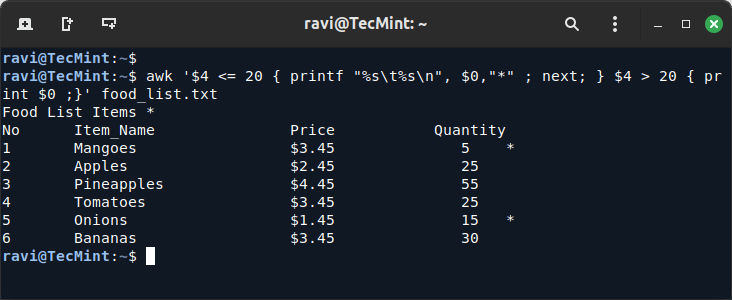
Here’s how it works:
- When a line meets the
$4 <= 20condition, it prints the line with an asterisk and then next skips the remaining actions for that line, moving directly to the next line. - This prevents the
$4 >l 20condition from being checked for lines already processed.
Example 2: Filtering and Formatting Data
Consider a file data.txt with the following content:
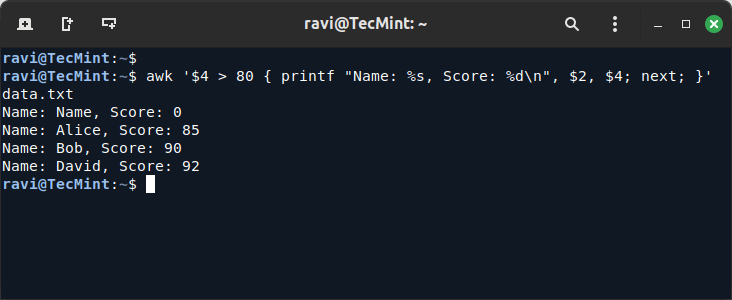
ID Name Age Score 1 Alice 30 85 2 Bob 25 90 3 Charlie 35 70 4 David 28 92
If you want to print only records where the score is above 80 and format them as “Name: [Name], Score: [Score]“, use:
awk '$4 > 80 { printf "Name: %s, Score: %d\n", $2, $4; next; }' data.txt
Summary
Using the next command in awk is a powerful way to streamline your data processing by avoiding unnecessary evaluations. By skipping the rest of the script for lines that have already been processed, you make your awk scripts more efficient and faster.
For those seeking a comprehensive resource, we’ve compiled all the Awk series articles into a book, that includes 13 chapters and spans 41 pages, covering both basic and advanced Awk usage with practical examples.
| Product Name | Price | Buy |
|---|---|---|
| eBook: Introducing the Awk Getting Started Guide for Beginners | $8.99 | [Buy Now] |
In the next part of our awk series, we’ll explore how to use standard input (STDIN) with awk. Stay tuned, and as always, feel free to share your thoughts and questions in the comments below!
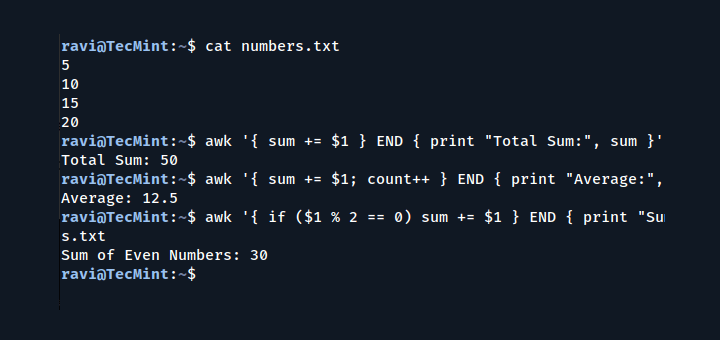





1) What is the different if I simply remove $4 > 20 { print $0, “-” ;} since it’s not processing at all?
awk ‘$4 <= 20 { printf "%s\t%s\n", $0,"*"}' food_list.txt
2) What does it do? printf "%s\t%s\n"
Each line is read twice to do the comparison if it is bigger than 20 or less than 20. What I believe this is doing is that once it found that the first condition was met it skips the second validation and goes to the next line.